Timestreamドキュメント
Timestream使用方法(プログラムからの使用)
- SDKから使用することを推奨
- しかしながら、REST APIも公開されているようで、SDKが対応していない言語や、SDKを使いたくない事情(全部マネージしたいとか?)があればREST APIを使うのもありらしい。
- REST APIを使用するには
Endpoint Discovery Patternを使ってEndpointを取得してから使うようです
- REST APIを使用するには
主な使用用途
- 時系列データを格納するのに向いている
- 株価の時間ごとの遷移
- 気温、気圧等時間で変化していくもの
などなど
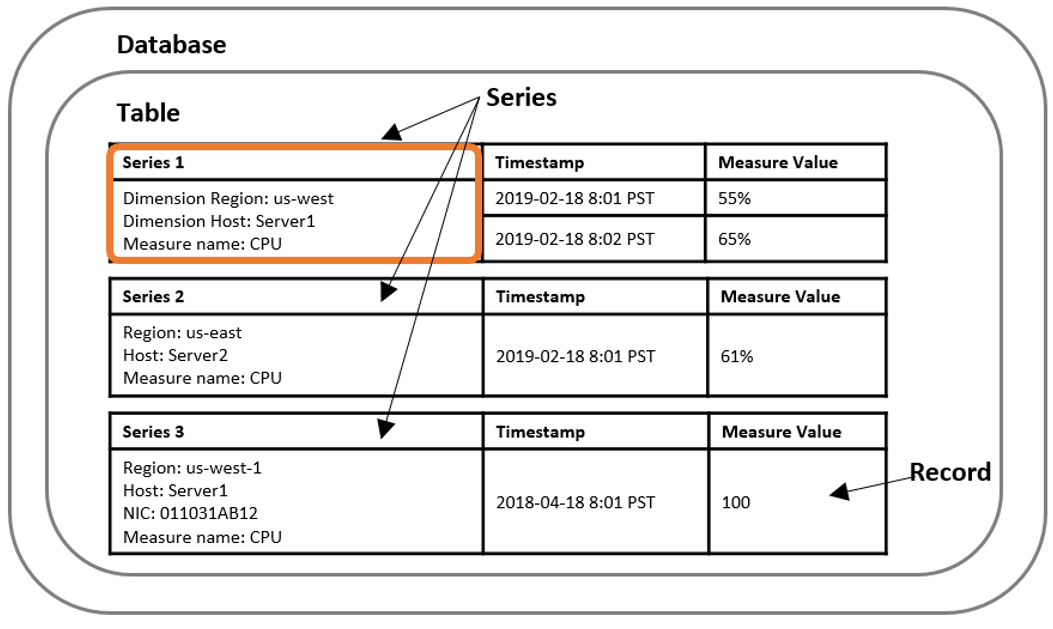
用語
- Time series
- 時間ごとに記録された1つ以上のデータのレコード
- 株価遷移
- CPU,メモリ使用率
- 時間ごとに記録された1つ以上のデータのレコード
- Record
- time seriesの1つのレコード
- Dimension
- 時系列データの属性を表すもの。Dimentionは名前と値で構成される。
- 例えば、"stock exchange"のDimension名称に対して"NYSE"等(証券取引所、に対してニューヨーク証券取引所)
- 時系列データの属性を表すもの。Dimentionは名前と値で構成される。
- Measure
- 実際のデータ
- 株価の値そのもの
- CPU,メモリ使用率
- 実際のデータ
- Timestamp
- 時間
- ナノ秒まで表現可能
- Table
- 関係のある時系列のセット。(RDBのテーブルと思ってOKかな)
- Database
データの書き込み
デフォルトの書き込みポリシーとしては先勝ちらしい。 追加のみ許可して、重複レコードはrejectのようす
基本は先勝ちルールなので、データの更新はできないが、後勝ちの書き込みルールに変更することもできる様子。 Upsertを有効にすることは可能のよう。
サポートしているデータタイプ
| タイプ | 概要 |
|---|---|
| BIGINT | 64ビットのint |
| BOOLEAN | bool |
| DOUBLE | 64bit, IEEE754準拠 |
| VARCHAR | 文字列。最大2KB |
ストレージ
データは新しいものはメモリに乗っているが、古いものは磁気メディアに移される。
Memory store retention- メモリ→磁気メディアへ移動する基準時間
Magnetic store retention- 磁気メディアからも削除される期間
暗号化
Timestreamはデフォルトでデータを暗号化する AWS Key Management Serviceのキーによって暗号化をすることも可能。
データの読み込み(Query)
SQLを使ってデータを取得することができる データをいくらあげようとも大丈夫、というレベルでスケールしてくれるらしい。 1日に数百TBあげても大丈夫だし、数百万の大小のクエリをなげても大丈夫、とのこと。
データModel
flat modelとtime series modelの2種類がある
Flat Model
- Timestreamのデフォルトのデータ形式
- 表形式でのデータ表現が可能
- dimension, time, measureなどを表敬式で表現する
- 表形式でのデータ表現が可能
| タイプ | 概要 |
|---|---|
| BIGINT | 64ビットのint |
| time | region | az | vpc | instance_id | measure_name | measure_value::double | measure_value::bigint |
|---|---|---|---|---|---|---|---|
| 2019-12-04 19:00:00.000000000 | us-east-1 | us-east-1d | vpc-1a2b3c4d | i-1234567890abcdef0 | cpu_utilization | 35 | null |
| 2019-12-04 19:00:01.000000000 | us-east-1 | us-east-1d | vpc-1a2b3c4d | i-1234567890abcdef0 | cpu_utilization | 38.2 | null |
Time series model
- 時系列データの解析用に使えるデータタイプだとか
- 表形式ではない
| region | az | vpc | instance_id | cpu_utilization |
|---|---|---|---|---|
| us-east-1 | us-east-1d | vpc-1a2b3c4d | i-1234567890abcdef0 | [{time: 2019-12-04 19:00:00.000000000, value: 35}, {time: 2019-12-04 19:00:01.000000000, value: 38.2}, {time: 2019-12-04 19:00:02.000000000, value: 45.3}] |
Go言語における制御
- sample
DBの接続情報取得
tr := &http.Transport{
ResponseHeaderTimeout: 20 * time.Second,
// Using DefaultTransport values for other parameters: https://golang.org/pkg/net/http/#RoundTripper
Proxy: http.ProxyFromEnvironment,
DialContext: (&net.Dialer{
KeepAlive: 30 * time.Second,
DualStack: true,
Timeout: 30 * time.Second,
}).DialContext,
MaxIdleConns: 100,
IdleConnTimeout: 90 * time.Second,
TLSHandshakeTimeout: 10 * time.Second,
ExpectContinueTimeout: 1 * time.Second,
}
// So client makes HTTP/2 requests
http2.ConfigureTransport(tr)
sess, err := session.NewSession(
&aws.Config{
Region: aws.String("us-east-1"),
MaxRetries: aws.Int(2),
HTTPClient: &http.Client{Transport: tr},
},
)
if err != nil {
panic(err)
}
// write service
writeSvc := timestreamwrite.New(sess)
// 事前に作ってあるdatabase名を取得する
// Describe database.
describeDatabaseInput := ×treamwrite.DescribeDatabaseInput{
DatabaseName: aws.String("sampleDB"),
}
describeDatabaseOutput, err := writeSvc.DescribeDatabase(describeDatabaseInput)
if err != nil {
fmt.Println("Error:")
fmt.Println(err)
} else {
fmt.Println("Describe database is successful, below is the output:")
fmt.Println(describeDatabaseOutput)
}
実行結果
# go run main.go
Describe database is successful, below is the output:
{
Database: {
Arn: "arn:aws:timestream:us-east-1:<aws-id>:database/sampleDB",
CreationTime: 2020-12-12 06:34:42.529 +0000 UTC,
DatabaseName: "sampleDB",
KmsKeyId: "arn:aws:kms:us-east-1:<aws-id>:key/<kms-key-id>",
LastUpdatedTime: 2020-12-12 06:34:42.52 +0000 UTC,
TableCount: 1
}
}
ちょっと解説
RDSなどのサービスと違い、databaseごとのエンドポイントが明示されるわけではない
SDKの内部的にはREST APIを操作していると思われるので、エンドポイントというのは存在するはずだが、それをSDKが隠してくれている
writeSvc := timestreamwrite.New(sess)
これで書き込み用のtimestreamとのセッションを作る
(今回書き込みをしたいわけではなく、DBの接続情報を表示したいだけだが、どうやらtimestreamwriteというパッケージ内にあるっぽい)
describeDatabaseInput := ×treamwrite.DescribeDatabaseInput{
DatabaseName: aws.String("sampleDB"),
}
describeDatabaseOutput, err := writeSvc.DescribeDatabase(describeDatabaseInput)
DB情報の取得。これをprintlnすることによって、上記のような出力結果を得ている
5件のレコード取得
package main import ( "fmt" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/timestreamquery" ) func main() { sess, err := session.NewSession(&aws.Config{Region: aws.String("us-east-1")}) querySvc := timestreamquery.New(sess) query := `SELECT * FROM sampleDB.IoT limit 5` fmt.Println("Submitting a query:") queryInput := ×treamquery.QueryInput{ QueryString: aws.String(query), } fmt.Println(queryInput) // submit the query queryOutput, err := querySvc.Query(queryInput) if err != nil { fmt.Println("Error:") fmt.Println(err) } fmt.Println(queryOutput) }
実行結果
# go run main.go
Submitting a query:
{
QueryString: "SELECT * FROM sampleDB.IoT limit 5"
}
// (説明のためにこれを追記)ここから下がQueryの結果
{
ColumnInfo: [
{
Name: "fleet",
Type: {
ScalarType: "VARCHAR"
}
},
{
Name: "truck_id",
Type: {
ScalarType: "VARCHAR"
}
},
{
Name: "fuel_capacity",
Type: {
ScalarType: "VARCHAR"
}
},
{
Name: "model",
Type: {
ScalarType: "VARCHAR"
}
},
{
Name: "load_capacity",
Type: {
ScalarType: "VARCHAR"
}
},
{
Name: "make",
Type: {
ScalarType: "VARCHAR"
}
},
{
Name: "measure_value::double",
Type: {
ScalarType: "DOUBLE"
}
},
{
Name: "measure_value::varchar",
Type: {
ScalarType: "VARCHAR"
}
},
{
Name: "measure_name",
Type: {
ScalarType: "VARCHAR"
}
},
{
Name: "time",
Type: {
ScalarType: "TIMESTAMP"
}
}
],
QueryId: "AEBQEAMY4TDJOQEQSLWL5HDJ6IQMPWG5OOJ62Q3RTFOSJZ64Z5OB7QBLWOXWECA",
Rows: [
{
Data: [
{
ScalarValue: "Alpha"
},
{
ScalarValue: "368680024"
},
{
ScalarValue: "100"
},
{
ScalarValue: "359"
},
{
ScalarValue: "1000"
},
{
ScalarValue: "Peterbilt"
},
{
ScalarValue: "309.0"
},
{
NullValue: true
},
{
ScalarValue: "load"
},
{
ScalarValue: "2020-12-12 02:13:08.917000000"
}
]
},
{
Data: [
{
ScalarValue: "Alpha"
},
{
ScalarValue: "368680024"
},
{
ScalarValue: "100"
},
{
ScalarValue: "359"
},
{
ScalarValue: "1000"
},
{
ScalarValue: "Peterbilt"
},
{
ScalarValue: "134.0"
},
{
NullValue: true
},
{
ScalarValue: "load"
},
{
ScalarValue: "2020-12-12 02:24:02.498000000"
}
]
...略
}
]
}
ちょっと解説
query := `SELECT * FROM sampleDB.IoT limit 5` fmt.Println("Submitting a query:") queryInput := ×treamquery.QueryInput{ QueryString: aws.String(query), } queryOutput, err := querySvc.Query(queryInput)
これがクエリを実行している部分。
クエリはSQLとして記載ができて、とてもわかりやすい。
データの追加
もちろんデータを追加することも可能
データの追加(wirte)するためには、"github.com/aws/aws-sdk-go/service/timestreamwrite"を使うらしい。
制約(2020/12/13追記)
- 1度にinsertできる最大のレコード数は100まで
// write service writeSvc := timestreamwrite.New(sess) databaseName := "sampleDB" tableName := "IoT" now := time.Now() currentTimeInMilliSeconds := now.UnixNano() currentTimeInMilliSeconds = int64(currentTimeInMilliSeconds / (1000 * 1000)) fmt.Println(currentTimeInMilliSeconds) writeRecordsInput := ×treamwrite.WriteRecordsInput{ DatabaseName: aws.String(databaseName), TableName: aws.String(tableName), Records: []*timestreamwrite.Record{ ×treamwrite.Record{ Dimensions: []*timestreamwrite.Dimension{ ×treamwrite.Dimension{ Name: aws.String("region"), Value: aws.String("us-east-1"), }, ×treamwrite.Dimension{ Name: aws.String("az"), Value: aws.String("az1"), }, ×treamwrite.Dimension{ Name: aws.String("hostname"), Value: aws.String("host1"), }, }, MeasureName: aws.String("cpu_utilization"), MeasureValue: aws.String("13.5"), MeasureValueType: aws.String("DOUBLE"), Time: aws.String(strconv.FormatInt(currentTimeInMilliSeconds, 10)), TimeUnit: aws.String(timestreamwrite.TimeUnitMilliseconds), }, ×treamwrite.Record{ Dimensions: []*timestreamwrite.Dimension{ ×treamwrite.Dimension{ Name: aws.String("region"), Value: aws.String("us-east-1"), }, ×treamwrite.Dimension{ Name: aws.String("az"), Value: aws.String("az1"), }, ×treamwrite.Dimension{ Name: aws.String("hostname"), Value: aws.String("host1"), }, }, MeasureName: aws.String("memory_utilization"), MeasureValue: aws.String("40"), MeasureValueType: aws.String("DOUBLE"), Time: aws.String(strconv.FormatInt(currentTimeInMilliSeconds, 10)), TimeUnit: aws.String(timestreamwrite.TimeUnitMilliseconds), }, }, } _, err = writeSvc.WriteRecords(writeRecordsInput) if err != nil { fmt.Println("Error:") fmt.Println(err) return } else { fmt.Println("Write records is successful") }
解説
2つのレコードを追記している。
なんとなく雰囲気でわかる気がする。
Dimensionsは、あとでqueryに使用することができる。このDimensionsの設計がかなり重要そうな予感。
Insertの結果の確認
SELECT * FROM sampleDB.IoT ORDER BY time DESC LIMIT 10
これをAWSコンソール上から実施してみる
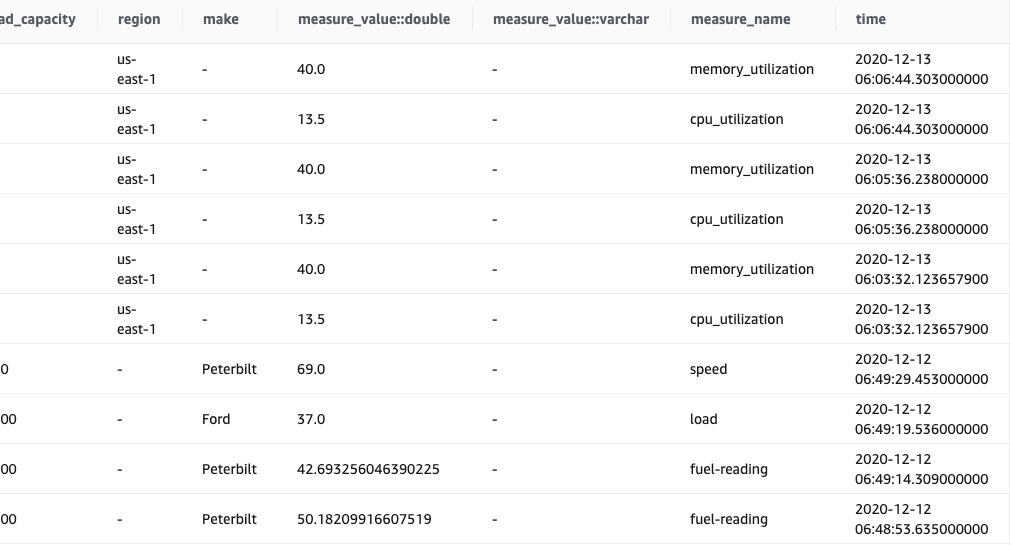
なんかいい感じ。
sampleで追加されたデータと、今回いれたデータが混在しているのがわかる。
非常に柔軟にデータを入れられる(NoSQLのように)くせに、SQLでクエリできるってのがすごい。
memory retention policyの範囲内の時間しかInsertできないぽい。
仮にmemory retention policyが1 dayだった場合、2日前のデータを入れようとすると時間がおかしいということでエラーがでるっぽい。
どうしても過去のデータを入れたい場合にはどうするんだろう?
複数テーブルのクエリについて
複数テーブルのクエリは許可されていない様子
Only one table is allowed per query. Tables found: 2
このようなエラーがでる
JOIN命令は使えるものの、1つのテーブルのJOINでしか使わないってことかな
Sample Queryにあるクエリ例
これも結合しているのはやはり1つのテーブルのみ("sampleDB".IoT)
-- Identify trucks that have been running on low fuel(less than 10 %) in the past 48 hours. WITH low_fuel_trucks AS ( SELECT time, truck_id, fleet, make, model, (measure_value::double/cast(fuel_capacity as double)*100) AS fuel_pct FROM "sampleDB".IoT WHERE time >= ago(48h) AND (measure_value::double/cast(fuel_capacity as double)*100) < 10 AND measure_name = 'fuel-reading' ), other_trucks AS ( SELECT time, truck_id, (measure_value::double/cast(fuel_capacity as double)*100) as remaining_fuel FROM "sampleDB".IoT WHERE time >= ago(48h) AND truck_id IN (SELECT truck_id FROM low_fuel_trucks) AND (measure_value::double/cast(fuel_capacity as double)*100) >= 10 AND measure_name = 'fuel-reading' ), trucks_that_refuelled AS ( SELECT a.truck_id FROM low_fuel_trucks a JOIN other_trucks b ON a.truck_id = b.truck_id AND b.time >= a.time ) SELECT DISTINCT truck_id, fleet, make, model, fuel_pct FROM low_fuel_trucks WHERE truck_id NOT IN ( SELECT truck_id FROM trucks_that_refuelled )